

Hier is een historisch tij dat je misschien niet kent. Tussen de jaren 1860 en 1940, toen het aantal Methodisten-ministers dat in New England woonde, toenam, nam ook de hoeveelheid Cubaanse rum die in Boston werd geïmporteerd - en beide namen op een zeer vergelijkbare manier toe. Dus, Methodisten dienaren moeten in die periode veel rum hebben opgekocht!
Eigenlijk niet, dat is een dwaze conclusie om te tekenen. Wat er echt aan de hand is, is dat beide hoeveelheden - methodistische ministers en Cubaanse rum - door andere factoren, zoals bevolkingsgroei, omhoog werden gedreven.
Om die verkeerde conclusie te trekken, hebben we de veel te veel voorkomende fout gemaakt verwarrende correlatie met oorzaak.
Wat is het verschil?
Er zijn twee hoeveelheden gecorreleerd als beide samen toenemen en afnemen ("positief gecorreleerd"), of als de ene toeneemt wanneer de andere afneemt en omgekeerd ("negatief gecorreleerd").
Correlatie wordt gemakkelijk gedetecteerd door statistische metingen van de Pearson's correlatiecoëfficiënt, wat aangeeft hoe strak opeengepakt de twee grootheden zijn, variërend van -1 (perfect negatief gecorreleerd) tot 0 (helemaal niet gecorreleerd) en tot 1 (perfect positief gecorreleerd).

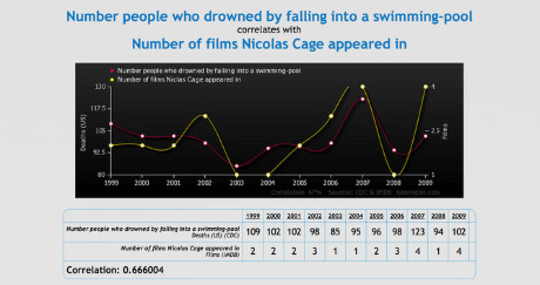 tylervigen.com
tylervigen.com
Maar alleen omdat twee grootheden worden gecorreleerd, betekent dit niet noodzakelijk dat iemand direct is veroorzakend de andere om te veranderen. Correlatie impliceert geen oorzaak, net zoals bewolkt weer geen regenval impliceert, ook al is het omgekeerde waar.
Als twee hoeveelheden worden gecorreleerd, is er mogelijk sprake van een echte oorzaak-gevolgrelatie (zoals neerslagniveaus en parapluverkopen), maar misschien drijven andere variabelen beide aan (zoals piratenaantallen en het broeikaseffect), of misschien is het gewoon toeval (zoals Amerikaans kaasgebruik en wurgingen-voor-bedlinnen).
Zelfs waar causaliteit aanwezig is, moeten we oppassen dat we de oorzaak niet vermengen met het effect, of anders concluderen we bijvoorbeeld dat een toenemend gebruik van verwarmingselementen kouder weer veroorzaakt.
Om oorzaak en gevolg vast te stellen, moeten we verder gaan dan de statistieken en zoeken naar afzonderlijke bewijzen (van wetenschappelijke of historische aard) en logisch redeneren. Correlatie kan ons in de eerste plaats ertoe brengen om naar dergelijk bewijs te zoeken, maar het is geenszins een bewijs op zich.
Subtiele problemen
Hoewel de bovenstaande voorbeelden overduidelijk dwaas waren, wordt correlatie vaak verward met het oorzakelijk verband op manieren die niet meteen duidelijk zijn in de echte wereld. Bij het lezen en interpreteren van statistieken moet men er goed op letten om precies te begrijpen wat de gegevens en de statistieken ervan impliceren - en wat nog belangrijker is, wat ze zijn niet impliceert.
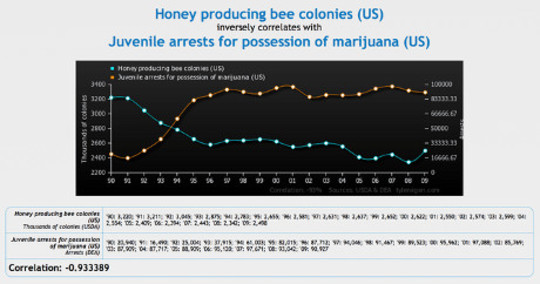
Een recent voorbeeld van de noodzaak van voorzichtigheid bij het interpreteren van gegevens is de opwinding eerder dit jaar rond de schijnbare grensverleggende detectie van gravitatiegolven - een aankondiging die lijkt te zijn gemaakt vroegtijdig, voordat alle variabelen die van invloed waren op de gegevens werden verantwoord.
Helaas is het analyseren van statistieken, kansen en risico's geen vaardigheidsset in ons menselijke intuïtieen zo is het al te gemakkelijk om op een dwaalspoor gebracht te worden. Volledige boeken zijn geschreven op de subtiele manieren waarop statistieken verkeerd kunnen worden geïnterpreteerd (of worden gebruikt om te misleiden). Om je te beschermen, volgen hier enkele veelvoorkomende gladde statistische problemen waarvan je op de hoogte moet zijn:
1) Het effect van een gezonde werker, waarbij soms twee groepen niet direct kunnen worden vergeleken op een gelijk speelveld.
Overweeg een hypothetische studie waarin de gezondheid van een groep kantoormedewerkers wordt vergeleken met de gezondheidstoestand van een groep astronauten. Als de studie geen significant verschil tussen de twee laat zien - geen correlatie tussen gezondheid en werkomgeving - moeten we dan concluderen dat wonen en werken in de ruimte op de lange termijn geen gezondheidsrisico's voor astronauten met zich meebrengt?
Nee! De groepen staan niet op één lijn: de aanvragers van het astronautenkorps zoeken naar gezonde kandidaten, die vervolgens een uitgebreid fitnessregime handhaven om proactief de effecten van leven in "microzwaartekracht" te bestrijden.
We verwachten daarom dat ze gemiddeld significant gezonder zijn dan kantoormedewerkers en dat ze zich terecht zorgen moeten maken als ze dat niet zijn.
2) Categorisering en het stadiummigratie-effect - schuifelen van mensen tussen groepen kan dramatische effecten hebben op statistische uitkomsten.
Dit staat ook bekend als de Will Rogers effect, na de Amerikaanse komiek die naar verluidt heeft gereageerd:
Toen de Okies Oklahoma verlieten en naar Californië verhuisden, verhoogden ze het gemiddelde intelligentieniveau in beide staten.
Ter illustratie, stel je voor dat je een grote groep vrienden opsplitst in een "korte" groep en een "lange" groep (misschien om ze voor een foto te regelen). Als je dit hebt gedaan, is het verrassend eenvoudig om de gemiddelde hoogte van beide groepen tegelijk te verhogen.
Vraag de kortste persoon in de "lange" groep om over te schakelen naar de "korte" groep. De "lange" groep verliest zijn kortste lid en stoot zo hun gemiddelde lengte omhoog - maar de "korte" groep krijgt zijn hoogste lid nog, en wint dus ook in gemiddelde lengte.
Dit heeft belangrijke implicaties voor medische onderzoeken, waarbij patiënten vaak worden gesorteerd in "gezonde" of "ongezonde" groepen tijdens het testen van een nieuwe behandeling. Als diagnostische methoden verbeteren, kunnen sommige zeer-enigszins-ongezonde patiënten worden gehercategoriseerd - wat leidt tot een verbetering van de gezondheidsresultaten van beide groepen, ongeacht hoe effectief (of niet) de behandeling is.
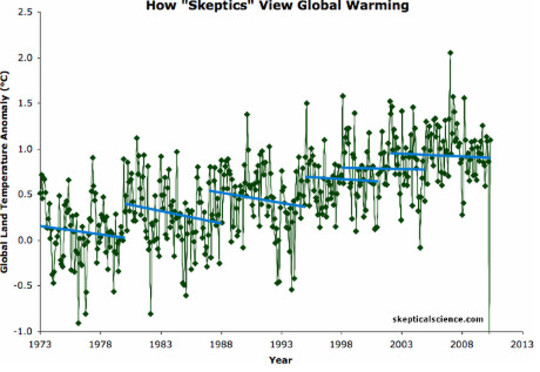 Plukken en kiezen uit de gegevens kan leiden tot de verkeerde conclusies. De sceptici zien de periode van afkoeling (blauw) wanneer de gegevens echt op de lange termijn opwarmen (groen). skepticalscience.com
Plukken en kiezen uit de gegevens kan leiden tot de verkeerde conclusies. De sceptici zien de periode van afkoeling (blauw) wanneer de gegevens echt op de lange termijn opwarmen (groen). skepticalscience.com
3) Datamining - wanneer een overvloed aan gegevens aanwezig is, kunnen stukjes en beetjes kers worden geplukt om elke gewenste conclusie te ondersteunen.
Dit is een slechte statistische praktijk, maar indien opzettelijk gedaan kan moeilijk te herkennen zijn zonder kennis van de originele, complete dataset.
Overweeg de bovenstaande grafiek die twee interpretaties van gegevens over de opwarming van de aarde weergeeft, bijvoorbeeld. Of fluoride - in kleine hoeveelheden is het een van de meest effectieve preventieve geneesmiddelen in de geschiedenis, maar het positieve effect verdwijnt volledig als men alleen maar rekening houdt met toxische hoeveelheden fluoride.
Om soortgelijke redenen is het belangrijk dat de procedures voor een bepaald statistisch experiment worden vastgelegd voordat het experiment begint en vervolgens ongewijzigd blijven totdat het experiment eindigt.
4) Clustering - wat te verwachten is, zelfs bij volledig willekeurige gegevens.
Overweeg een medisch onderzoek naar hoe een bepaalde ziekte, zoals kanker of multiple sclerose, is geografisch verdeeld. Als de ziekte willekeurig toeslaat (en de omgeving heeft geen effect), zouden we verwachten dat een groot aantal clusters van patiënten vanzelfsprekend zijn. Als patiënten perfect gelijkmatig verdeeld zijn, zou de verdeling hoogst onwillekeurig zijn!
Dus de aanwezigheid van een enkele cluster, of een aantal kleine clusters van gevallen, is volkomen normaal. Geavanceerde statistische methoden zijn nodig om te bepalen hoeveel clustering nodig is om te concluderen dat iets in dat gebied de ziekte kan veroorzaken.
Helaas zorgt een cluster - zelfs een niet-significante - voor een eenvoudige (en op het eerste gezicht aantrekkelijke) nieuwskop.

Statistische analyses, net als elk ander krachtig hulpmiddel, moeten zeer zorgvuldig worden gebruikt - en in het bijzonder moet men altijd voorzichtig zijn bij het trekken van conclusies op basis van het feit dat twee hoeveelheden met elkaar in verband staan.
In plaats daarvan moeten we altijd aandringen op afzonderlijke bewijzen om te pleiten voor oorzaak en gevolg - en dat bewijsmateriaal zal niet in de vorm van één enkel statistisch nummer komen.
Schijnbaar dwingende correlaties, zeg tussen gegeven genen en schizofrenie of tussen een hoog vet dieet en hartziekten, kan blijken te zijn gebaseerd op zeer dubieuze methodologie.
We zijn misschien als een soort die cognitief slecht is voorbereid om met deze problemen om te gaan. Als Canadese opvoeder Kieran Egan stop het in zijn boek Verkeer vanaf het begin:
Het slechte nieuws is dat onze evolutie ons in staat stelde om te leven in kleine, stabiele jager-verzamelaarsamenlevingen. Wij zijn Pleistoceen mensen, maar onze languaged hersenen hebben enorme, multiculturele, technologisch geavanceerde en snel veranderende samenlevingen gecreëerd voor ons om in te leven.
Dientengevolge moeten we voortdurend de verleiding weerstaan om betekenis in toeval te zien en correlatie en oorzaak te verwarren.![]()
Dit artikel is oorspronkelijk gepubliceerd op The Conversation
Lesen Sie hier originele artikel.
Over de auteurs
 Jonathan Borwein (Jon) is laureaat hoogleraar wiskunde aan de universiteit van Newcastle. Hij is laureaat hoogleraar wiskunde aan de universiteit van Newcastle en directeur van het centrum voor computergestuurd onderzoek, wiskunde en toepassingen (CARMA). Hij heeft gewerkt bij Carnegie-Melon, Dalhousie, Simon Fraser en Waterloo Universities en heeft twee Canada Research Chairs in de informatica gehouden.
Jonathan Borwein (Jon) is laureaat hoogleraar wiskunde aan de universiteit van Newcastle. Hij is laureaat hoogleraar wiskunde aan de universiteit van Newcastle en directeur van het centrum voor computergestuurd onderzoek, wiskunde en toepassingen (CARMA). Hij heeft gewerkt bij Carnegie-Melon, Dalhousie, Simon Fraser en Waterloo Universities en heeft twee Canada Research Chairs in de informatica gehouden.
 Michael Rose is een PhD Candidate, School of Mathematical and Physical Sciences aan de University of Newcastle. Promovendus in de demografie onder toezicht van Laureaat prof. Jon Borwein aan de universiteit van Newcastle, Australië. Momenteel assisteren bij onderzoek naar het toepassen van fractal wiskunde op het modelleren van hersynapsverdelingen.
Michael Rose is een PhD Candidate, School of Mathematical and Physical Sciences aan de University of Newcastle. Promovendus in de demografie onder toezicht van Laureaat prof. Jon Borwein aan de universiteit van Newcastle, Australië. Momenteel assisteren bij onderzoek naar het toepassen van fractal wiskunde op het modelleren van hersynapsverdelingen.
Disclosure Statement: De auteurs werken niet voor, hebben geen advies over, hebben geen aandelen in of ontvangen geen geld van een bedrijf of organisatie dat van dit artikel zou profiteren. Ze hebben ook geen relevante voorkeuren.
Aanbevolen boek:
Geld, seks, oorlog, karma: aantekeningen voor een boeddhistische revolutie
door David R. Loy.
 David Loy is een van de meest krachtige pleitbezorgers van het boeddhistische wereldbeeld geworden en legt als geen ander de mogelijkheid om het sociaal-politieke landschap van de moderne wereld te transformeren. In Geld, seks, oorlog, karma, hij biedt scherpe en zelfs schokkend duidelijke presentaties van vaak verkeerd begrepen boeddhistische nietjes - de werking van karma, de aard van het zelf, de oorzaken van problemen op zowel het individuele als het sociale niveau - en de echte redenen achter ons collectieve gevoel van "nooit genoeg" , "of het nu tijd, geld, seks, veiligheid ... zelfs oorlog is. De "Boeddhistische Revolutie" van David is niets minder dan een radicale verandering in de manieren waarop we ons leven, onze planeet, de collectieve wanen die onze taal, onze cultuur en zelfs onze spiritualiteit doordringen, kunnen benaderen.
David Loy is een van de meest krachtige pleitbezorgers van het boeddhistische wereldbeeld geworden en legt als geen ander de mogelijkheid om het sociaal-politieke landschap van de moderne wereld te transformeren. In Geld, seks, oorlog, karma, hij biedt scherpe en zelfs schokkend duidelijke presentaties van vaak verkeerd begrepen boeddhistische nietjes - de werking van karma, de aard van het zelf, de oorzaken van problemen op zowel het individuele als het sociale niveau - en de echte redenen achter ons collectieve gevoel van "nooit genoeg" , "of het nu tijd, geld, seks, veiligheid ... zelfs oorlog is. De "Boeddhistische Revolutie" van David is niets minder dan een radicale verandering in de manieren waarop we ons leven, onze planeet, de collectieve wanen die onze taal, onze cultuur en zelfs onze spiritualiteit doordringen, kunnen benaderen.
Klik hier voor meer info en / of om dit boek op Amazon te bestellen.



















