

Twee jaar geleden kondigde oud-president Barack Obama de Precision Medicine-initiatief in zijn State of the Union-toespraak. Het initiatief streefde naar een "nieuw tijdperk van de geneeskunde", waarin ziektebehandelingen specifiek zouden kunnen worden afgestemd op de genetische code van elke patiënt. ![]()
Dit resoneerde goed in de kankergeneeskunde. Patiënten kunnen hun kanker al beheersen met therapieën die gericht zijn op de specifieke genen die in hun specifieke tumor zijn veranderd. Vrouwen met een type borstkanker veroorzaakt door de amplificatie van gen HER2 worden bijvoorbeeld vaak behandeld met een therapeutisch middel dat herceptin wordt genoemd. Omdat deze gerichte therapieën specifiek zijn voor kankercellen, hebben ze meestal minder bijwerkingen dan traditionele kankerbehandelingen met chemotherapie of bestraling.
Dergelijke behandelingen zijn echter niet beschikbaar voor de meeste kankerpatiënten. Bij veel kankers blijven de specifieke genetische veranderingen die verantwoordelijk zijn voor kanker onbekend. Om geïndividualiseerde kankerbehandelingen te creëren, moeten we meer weten over de functionele genetische veranderingen.
Nu gegevens over de genetica van kanker snel groeien, kunnen wiskunde en statistiek nu helpen de verborgen patronen in deze gegevens te ontrafelen om de genen te vinden die verantwoordelijk zijn voor de kanker van een individu. Met deze kennis kunnen artsen geschikte behandelingen selecteren die de werking van deze genen blokkeren om therapieën voor individuele patiënten te personaliseren. Mijn onderzoek heeft tot doel precisiegeneeskunde bij kanker te verbeteren - door voort te bouwen op dezelfde methoden die zijn gebruikt om patronen in Netflix-filmbeoordelingen te vinden.
Door de gegevens bladeren
Tegenwoordig is er een ongekende openbare toegang tot gegevens over kankergenetica. Deze gegevens zijn afkomstig van gulle patiënten die hun tumormonsters doneren voor onderzoek. Wetenschappers passen vervolgens sequencingtechnologieën toe om de mutaties en activiteit in elk van de 20,000 genen in het menselijk genoom te meten.

Al deze gegevens zijn een direct gevolg van de Menselijk genoom project in 2003. Dat project bepaalde de volgorde van alle genen waaruit gezond menselijk DNA bestaat. Sinds de voltooiing van dat project zijn de kosten van het sequencen van het menselijk genoom gestegen elk jaar meer dan gehalveerd, die de groei van rekenkracht overtreft die wordt beschreven in Wet van Moore. Deze kostenverlaging stelt onderzoekers in staat om ongekende genetische gegevens van kankerpatiënten te verzamelen.
De meeste wetenschappelijke onderzoeken naar kankergenetica die wereldwijd zijn uitgevoerd, geven hun gegevens vrij aan een gecentraliseerde, openbare database die wordt aangeboden door de National Institutes of Health (NIH) National Library of Medicine van de VS. Het NIH National Cancer Institute en National Human Genome Research Institute hebben ook vrijelijk genetische gegevens vrijgegeven van meer dan 11,000 tumoren in 33 soorten kanker via een project genaamd De kankergenoomatlas.
Elke biologische functie – van het onttrekken van energie aan voedsel tot het genezen van een wond – is het resultaat van activiteit in verschillende combinaties van genen. Kankers kapen de genen die mensen in staat stellen volwassen te worden en die het lichaam beschermen tegen het immuunsysteem. Onderzoekers noemen deze de "kenmerken van kanker." Door deze zogenaamde ontregeling van genen kan een tumor ongecontroleerd groeien en uitzaaiingen vormen in organen die ver van de oorspronkelijke tumorplaats verwijderd zijn.
Onderzoekers gebruiken deze openbare gegevens actief om de reeks genveranderingen te vinden die verantwoordelijk zijn voor elk tumortype. Maar dit probleem is niet zo eenvoudig als het identificeren van een enkel ontregeld gen in elke tumor. Honderden, zo niet duizenden, van de 20,000 genen in het menselijk genoom zijn ontregeld bij kanker. De groep van ontregelde genen varieert in de tumor van elke patiënt, met kleinere sets van vaak hergebruikte genen die elk kenmerk van kanker mogelijk maken.
Precisiegeneeskunde is gebaseerd op het vinden van de kleinere groepen ontregelde genen die verantwoordelijk zijn voor de biologische functie in de tumor van elke patiënt. Maar genen kunnen meerdere biologische functies hebben in verschillende contexten. Daarom moeten onderzoekers een reeks "overlappende" genen ontdekken die gemeenschappelijke functies hebben bij een reeks kankerpatiënten.
Het koppelen van genstatus aan functie vereist complexe wiskunde en enorme rekenkracht. Deze kennis is essentieel om de uitkomst van therapieën te voorspellen die de functie van deze genen zouden blokkeren. Dus, hoe kunnen we die overlappende kenmerken ontdekken om individuele uitkomsten voor patiënten te voorspellen?
Wat Netflix ons kan leren
Gelukkig voor ons is dit probleem al opgelost in de informatica. Het antwoord is een klasse technieken die 'matrixfactorisatie' wordt genoemd – en u hebt waarschijnlijk al met deze technieken in uw dagelijks leven te maken gehad.
In 2009, Netflix had een uitdaging om filmbeoordelingen voor elke Netflix-gebruiker te personaliseren. Op Netflix heeft elke gebruiker een aparte reeks beoordelingen van verschillende films. Hoewel twee gebruikers dezelfde filmsmaak kunnen hebben, kunnen ze enorm verschillen in specifieke genres. Daarom kunt u niet vertrouwen op het vergelijken van beoordelingen van vergelijkbare gebruikers.
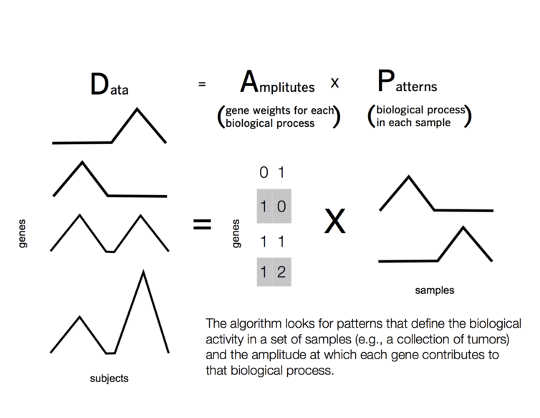
In plaats daarvan vindt een algoritme voor matrixfactorisatie films met vergelijkbare beoordelingen bij een kleinere groep gebruikers. De groep gebruikers verschilt per film. De computer associeert elke gebruiker in verschillende mate met een groep films, op basis van hun individuele smaak. De relaties tussen gebruikers worden 'patronen' genoemd. Deze patronen worden uit de gegevens geleerd en kunnen gemeenschappelijke ranglijsten vinden die alleen door het filmgenre niet waren voorzien - gebruikers kunnen bijvoorbeeld een voorkeur voor een bepaalde regisseur of acteur delen.
 Genevieve Stein-O'Brien, CC BY
Genevieve Stein-O'Brien, CC BY
Hetzelfde proces kan werken bij kanker. In dit geval zijn de metingen van ontregeling van genen analoog aan filmbeoordelingen, filmgenres aan biologische functie en gebruikers aan tumoren van patiënten. De computer doorzoekt tumoren van patiënten om patronen te vinden in ontregeling van genen die de kwaadaardige biologische functie in elke tumor veroorzaken.
Van films tot tumoren
De analogie tussen filmbeoordelingen en kankergenetica valt uiteen in de details. Tenzij ze minderjarig zijn, worden Netflix-gebruikers niet beperkt in de films die ze bekijken. Maar ons lichaam geeft er de voorkeur aan om het aantal genen dat voor een enkele functie wordt gebruikt, te minimaliseren. Er zijn ook substantiële redundanties tussen genen. Om een cel te beschermen, kan het ene gen gemakkelijk het andere vervangen om een gemeenschappelijke functie te vervullen. Genfuncties bij kanker zijn zelfs nog complexer. Tumoren zijn ook zeer complex en evolueren snel, afhankelijk van willekeurige interacties tussen de kankercellen en het aangrenzende gezonde orgaan.
Om rekening te houden met deze complexiteiten, hebben we een benadering voor matrixfactorisatie ontwikkeld, genaamd Gecoördineerde genactiviteit in patroonsets - of kortweg CoGAPS. Ons algoritme verklaart het minimalisme van de biologie door zo min mogelijk genen op te nemen in de patronen voor elke tumor.
Verschillende genen kunnen elkaar ook vervangen, elk met een vergelijkbare functie in een andere context. Om dit te verklaren, schat CoGAPS tegelijkertijd een statistiek voor de zogenaamde "patronen" van genfunctie. Dit stelt ons in staat om de waarschijnlijkheid te berekenen dat elk gen wordt gebruikt in elke biologische functie in een tumor.
Veel patiënten gebruiken bijvoorbeeld een gericht therapeutisch middel, cetuximab genaamd, om de overleving bij darm-, alvleesklier-, long- en mondkanker te verlengen. Ons recente werk heeft aangetoond dat deze patronen de genfunctie kunnen onderscheiden in kankercellen die reageren op het gerichte therapeutische middel cetuximab en degenen die dat niet doen.
De toekomst
Helaas kunnen kankertherapieën die gericht zijn op genen de ziekte van een patiënt meestal niet genezen. Ze kunnen de progressie slechts een paar jaar vertragen. De meeste patiënten vallen dan terug, met tumoren die niet meer reageren op de behandeling.
Ons eigen recente werk ontdekte dat de patronen die de genfunctie onderscheiden in cellen die reageren op cetuximab, de genen omvatten die aanleiding geven tot resistentie. Opkomende immunotherapieën zijn veelbelovend en lijken sommige vormen van kanker te genezen. Maar veel te vaak vallen patiënten met deze behandelingen ook terug. Nieuwe gegevens die de kankergenetica na behandeling volgen, zijn essentieel om te bepalen waarom patiënten niet langer reageren.
Naast deze gegevens heeft kankerbiologie ook een nieuwe generatie wetenschappers nodig die wiskunde en statistiek kunnen overbruggen om de genetische veranderingen te bepalen die in de loop van de tijd optreden bij resistentie tegen geneesmiddelen. Op andere gebieden van de wiskunde kunnen computerprogramma's resultaten op de lange termijn voorspellen. Deze modellen worden vaak gebruikt in weersvoorspellingen en investeringsstrategieën.
Op deze gebieden en mijn eigen eerdere onderzoekhebben we geconstateerd dat updates van de modellen van grote datasets – zoals satellietgegevens in het geval van weer – langetermijnvoorspellingen verbeteren. We hebben allemaal het effect van deze updates gezien, met weersvoorspellingen die verbeteren naarmate we dichter bij een storm komen.
Net zoals tools uit de computerwetenschap die worden gebruikt kunnen worden aangepast aan zowel filmaanbevelingen als kanker, zal de toekomstige generatie computationele wetenschappers voorspellingstools uit een reeks gebieden voor precisiegeneeskunde gebruiken. Uiteindelijk hopen we met deze computationele hulpmiddelen de reactie van tumoren op therapie net zo vaak te voorspellen als we het weer voorspellen, en misschien betrouwbaarder.
Over de auteur
Elana Fertig, Universitair Docent Oncologische Biostatistiek en Bioinformatica, Johns Hopkins University
Dit artikel is oorspronkelijk gepubliceerd op The Conversation. Lees de originele artikel.
Verwante Boeken
at InnerSelf Market en Amazon

















